
OVERVIEW
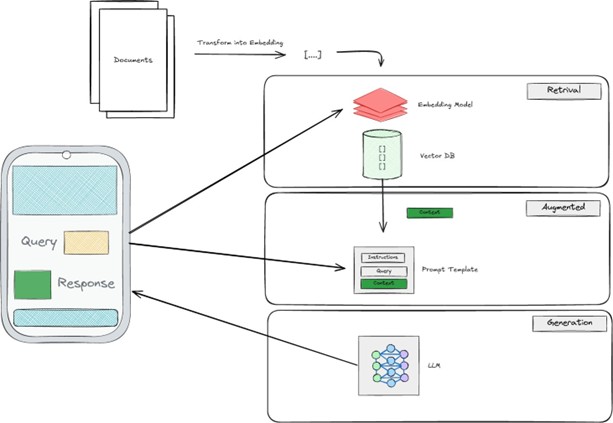
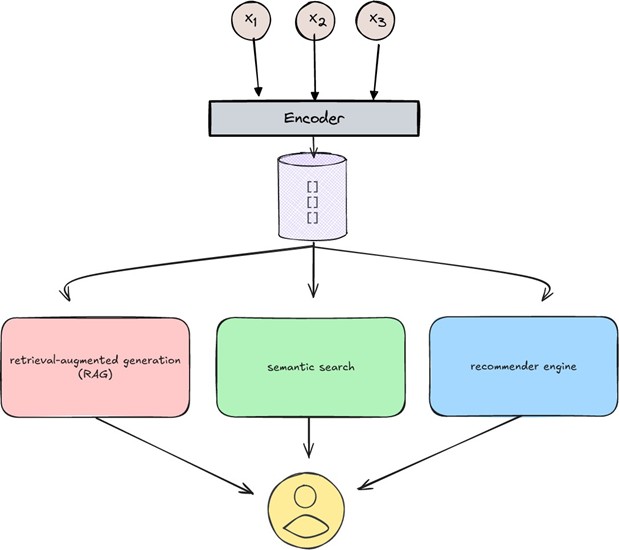
Figure 1: RAG Layers and Interactions
Understanding Vector Infrastructure: From Data to Dimensions
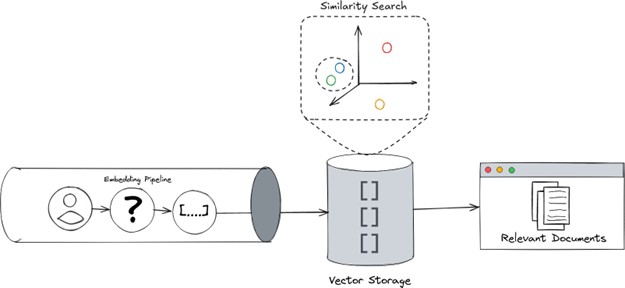
The Art of Organization: Rapid Similarity Search
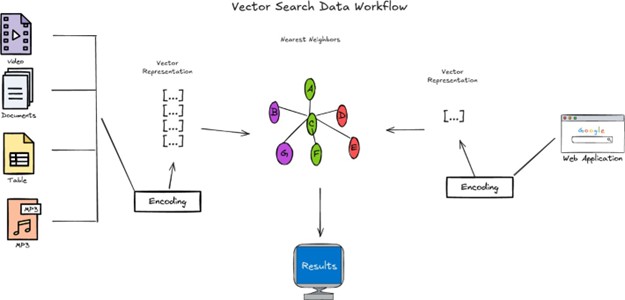
Unpacking the Engine: Dense Indexing, Filtering, and Hybrid Search
1. Dense Indexing Strategies
To avoid the performance bottleneck of exact searches, vector databases employ sophisticated indexing techniques. These indexes create data structures that pre-organize the vectors, allowing the search algorithm to quickly narrow down the search space to the most relevant regions. Two of the most prominent indexing algorithms are:
Hierarchical Navigable Small World (HNSW): This graph-based technique builds a multi-layered network where vectors (nodes) are connected to their nearest neighbors. Searches start at the sparsest top layer to quickly navigate to the approximate region of interest and then move to denser, lower layers for a more precise search.
Figure 6: Example of an HNSW and IVF Index Search (Bang for the Buck: Vector Search on Cloud CPUs)
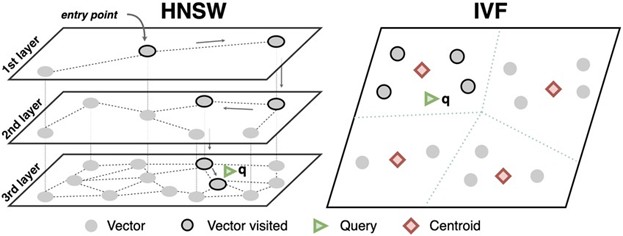
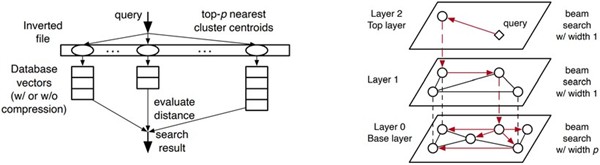
Inverted File (IVF): The IVF index uses a clustering algorithm, like k-means, to group vectors into partitions. When a query is executed, the system identifies the most relevant partitions (or clusters) and searches only within that subset, drastically reducing the number of vectors that need to be compared. The Oracle AI Vector Search, for instance, supports both IVF and HNSW indexing methods (Hirschfeld et al.).
2. Filtering Strategies
In many enterprise applications, semantic similarity alone is not enough. A query often needs to be constrained by metadata, such as a document’s creation date, author, or source. Vector infrastructure supports this through filtering, which can be applied in several ways:
- Pre-filtering: The system first applies metadata filters to narrow down the dataset and then performs the vector search on the resulting subset. This is highly efficient when the filters are very selective.
- Post-filtering: The vector search is performed first to retrieve the top similar vectors, and the metadata filters are applied afterward. This approach is simpler but can be inefficient if a large portion of the retrieved results are filtered out.
Efficiently combining metadata filters with vector search is a key challenge, but modern vector databases are increasingly offering sophisticated query planners to optimize this process.
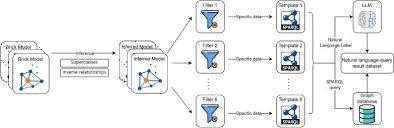
Figure 8: BuildingGPT: Query Building Semantic Data Using Large Language Models and Vector-graph Retrieval-augmented Generation.
Unpacking the Engine: Dense Indexing, Filtering, and Hybrid Search
Anchoring AI in Reality: Vector Systems in the Enterprise
In enterprise environments, the ability to deliver scalable, trustworthy, and high-fidelity AI responses is paramount. Vector infrastructure is the anchor that makes this possible. By storing and indexing embeddings from a company’s proprietary knowledge base—whether it’s internal documents, customer support tickets, or product manuals—vector systems provide the grounding data that RAG needs to function effectively.
This grounding ensures that the LLM’s responses are not just fluent but are also based on factual, up-to-date, and company-specific information, dramatically reducing the likelihood of hallucinations. Furthermore, because vector databases are designed for horizontal scalability, they can handle the petabyte-scale embedding data that large enterprises generate, all while maintaining the low-latency retrieval speeds required for real-time applications like chatbots and recommendation engines.
Recommendation Engines and Semantic Search
Recommendation engines have become a cornerstone of personalization, and their integration with semantic search within a vector infrastructure represents a significant leap forward. Traditional recommendation systems, which often rely on collaborative or content-based filtering, can be enhanced by the deep contextual understanding that semantic search provides (IBM, “What is a Recommendation Engine?”). By converting items and user preferences into vector embeddings, a recommendation engine can identify and suggest items based on their conceptual meaning rather than simple keyword matches or co-occurrence (Enterprise Knowledge).
This process begins by transforming data—such as product descriptions, article text, or user interaction history—into high-dimensional vectors. When a user shows interest in an item, the system can search the vector space for other items that are “close” in meaning, uncovering novel and relevant suggestions that might otherwise be missed. This allows the system to understand nuanced queries and preferences, delivering a more personalized and engaging user experience.
Advantages of Using Semantic Search for Improving Recommendation Accuracy
The primary advantage of using semantic search is its ability to move beyond literal keyword matching to understand the intent and context behind user behavior and item characteristics. This leads to several key benefits for recommendation accuracy:
- Improved Relevance and Personalization: By understanding the meaning of items, semantic search can deliver highly relevant recommendations that align with a user’s true interests, even when expressed in ambiguous or conversational language. This enhances personalization and leads to higher user satisfaction and engagement.
- Overcoming the “Cold Start” Problem: Traditional recommenders struggle when new users or items have no interaction history. Semantic search mitigates this by analyzing the item’s descriptive content. A new item can be recommended immediately based on its semantic similarity to other items or user queries, without needing historical interaction data.
Discovery of Novel and Serendipitous Items: Semantic search can uncover conceptually related items that do not share explicit attributes or co-purchase history. This helps users discover new products or content they might not have found on their own, broadening their interests and increasing engagement. For example, a user interested in “dystopian science fiction novels” could be recommended as a conceptually similar film or graphic novel, even if the metadata tags do not perfectly align.
Real-World Implementation Scenarios
Technology Frameworks: For an organization like the National Institute of Standards and Technology, a semantic recommendation engine can help users discover relevant guidance. A developer searching for “best practices for securing a cloud-native application” could be recommended not only the primary “Secure Software Development Framework. but also related publications on container security and API protection, even if their query does not contain those exact terms. The system understands the semantic relationship between “cloud-native security” and its constituent components, providing a more comprehensive set of resources.

Safety Research: The National Transportation Safety Board (NTSB) maintains a vast database of accident reports. A semantic recommendation engine could help investigators by proactively suggesting related incidents. For instance, an investigator reviewing a report on a “runway incursion involving a ground vehicle” could be automatically recommended other reports describing similar events, such as “taxiway deviations” or “unauthorized vehicle on runway,” even if the terminology differs. This ensures that investigators have access to a broader context of similar safety events, potentially revealing systemic risks that might otherwise be overlooked.
Vector infrastructure is more than just a storage solution; it is the high-performance engine at the core of modern, retrieval-augmented AI and personalized digital experiences. By efficiently organizing semantically encoded data, it enables not only rapid similarity search, strategic filtering, and powerful hybrid search capabilities but also the intelligent recommendation engines that drive user engagement. For enterprises looking to build scalable, accurate, and trustworthy AI applications that are also deeply personalized, understanding and investing in a robust vector infrastructure is no longer optional—it is the foundation for the future.

References
“Enable and Use Pgvector in Azure Database for PostgreSQL.” Microsoft Learn, 11 Mar. 2025, learn.microsoft.com/en-us/azure/postgresql/flexible-server/how-to-use-pgvector.
“What Is a Vector Database?” Google Cloud, Google, cloud.google.com/discover/what-is-a-vector-database?hl=en. Accessed 23 Oct. 2025.
“What Is Vector Search?” Elastic, www.elastic.co/what-is/vector-search. Accessed 23 Oct. 2025.
Hirschfeld, Sarah, et al. Oracle® AI Database: Oracle AI Vector Search User’s Guide. Version 26ai, Oracle, Oct. 2025.
“5 Steps For Building Your Enterprise Semantic Recommendation Engine.” Enterprise Knowledge, 10 Oct. 2023, enterpriseknowledge.com/5-steps-for-building-your-enterprise-semantic-recommendation-engine/. Accessed 30 Oct. 2025.
“Enable and Use Pgvector in Azure Database for PostgreSQL.” Microsoft Learn, 11 Mar. 2025, learn.microsoft.com/en-us/azure/postgresql/flexible-server/how-to-use-pgvector.
Google Cloud. “Recommendation overview.” Google Cloud, cloud.google.com/bigquery/docs/recommendation-overview. Accessed 30 Oct. 2025.
Google Cloud. “What is semantic search, and how does it work?” Google Cloud, cloud.google.com/learn/what-is-semantic-search. Accessed 30 Oct. 2025.
Google Developers. “Overview/Types.” Google Developers, developers.google.com/machine-learning/recommendation/overview/types. Accessed 30 Oct. 2025.
Hirschfeld, Sarah, et al. Oracle® AI Database: Oracle AI Vector Search User’s Guide. Version 26ai, Oracle, Oct. 2025.
IBM. “Project: Recommendations with IBM.” IBM, www.ibm.com/think/topics/recommendation-engine. Accessed 30 Oct. 2025.
IBM. “What is a Recommendation Engine?” IBM, 2024, www.ibm.com/topics/recommendation-engine.
NVIDIA. “What is a Recommendation System?” NVIDIA, www.nvidia.com/en-us/glossary/recommendation-system/. Accessed 30 Oct. 2025.
“Semantic Search and Recommendation Algorithm.” arXiv, 9 Dec. 2024, arxiv.org/abs/2412.06543. Accessed 30 Oct. 2025.
“Vector Databases for AI Applications: Building Semantic Search Systems.” Devsatva, 28 Jan. 2025, devsatva.com/vector-databases-for-ai-applications-building-semantic-search-systems/. Accessed 30 Oct. 2025.