
OVERVIEW
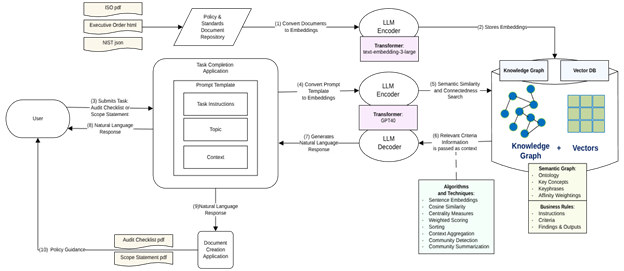
Figure 1: Hybrid Retrieval-Augment Generation (RAG) Architecture Diagram
THE FOUNDATION: FROM DATA TO MEANING WITH VECTOR EMBEDDINGS
At its core, semantic encoding is the process of converting unstructured data, such as text or images, into a numerical format that machine learning models can understand and process (IBM, “What is Vector Embedding?”).
These numerical representations, illustrated in Figure 2, called vector embeddings, are not just random numbers; they are carefully crafted to capture the semantic essence—the meaning and context—of the original data.
An embedding model, often a complex neural network, is trained on vast datasets to learn the relationships and patterns within the data.
The result is a high-dimensional vector, an array of numbers, where the position and direction of the vector in a multi-dimensional space correspond to the data’s meaning (IBM, “What is Embedding?”).
The power of this approach lies in its ability to represent similarity.
Data points with similar meanings will have vector embeddings that are close to each other in this “vector space.”
For instance, the words ‘coffee’ and ‘tea’ would be mapped to vectors that are spatially closer than the vector for ‘astronomy’ (AWS, “What are Vector Embeddings?”).
This proximity allows algorithms to perform semantic searches, finding not just exact keyword matches but also conceptually related information (Google Cloud, “Vector Search”).
This capability is a fundamental building block for more advanced AI applications, from recommendation engines to complex question-answering systems (AWS, “Vector Databases and Embeddings”).
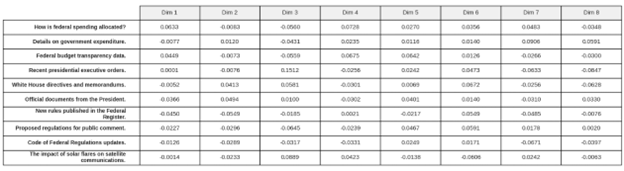
Figure 2: Numerical Vector Representation
SENTENCE TRANSFORMERS: ENCODING THE MEANING OF SENTENCES
While early embedding techniques focused on individual words, modern applications often require understanding the meaning of entire sentences or paragraphs. This is where sentence transformers come into play. Sentence transformers are a class of models specifically fine-tuned to generate embeddings for whole sentences and short paragraphs (IBM, “Supported embedding models available with watsonx.ai”). These models, often based on transformer architectures like BERT, are designed to produce a single vector that encapsulates the holistic meaning of a sequence of words. Figure 3 illustrates usage of a scatter plot using PCA to visualize semantic similarity.
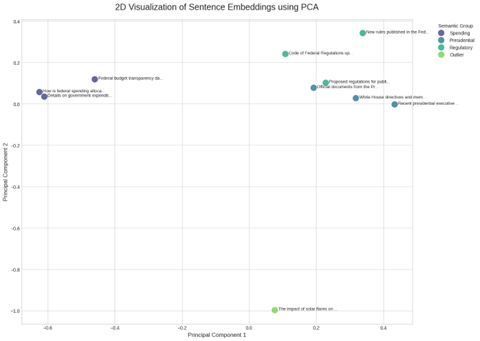
Figure 3: Scatter Plot Using PCA to Visualize Semantic Similarity.
For example, a model like all-MiniLM-L6-v2, available through providers like IBM and the open-source community, takes a sentence as input and outputs a vector that captures its semantic information (IBM, “Supported embedding models available with watsonx.ai”). This is crucial for tasks like semantic textual similarity, where the goal is to determine how alike two pieces of text are in meaning (Sentence Transformers). By converting sentences into these dense vector representations, we can use mathematical calculations, such as cosine similarity, to measure the “distance” between their meanings. A smaller distance implies a higher degree of semantic similarity (AWS, “Vector Databases and Embeddings”). This technique is foundational for clustering documents, information retrieval, and paraphrase detection (IBM, “Supported embedding models available with watsonx.ai”).
PREPARING DATA FOR RETRIEVAL-AUGMENTED GENERATION (RAG)
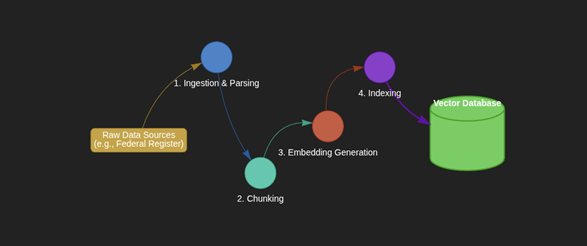
Figure 4: Preparing Data for RAG System.
The data preparation pipeline would involve the following key stages:
- Ingestion and Parsing: The first step is to gather the raw, unstructured data from our sources. This includes documents, web pages, and other text-based files. For example, we would ingest presidential executive orders from the Federal Register or data model specifications from the Federal Spending Transparency site. Specialized libraries can then be used to parse this raw data, extracting the clean text from formats like PDFs or HTML (Databricks, “Build an unstructured data pipeline for RAG”).
- Chunking: Since LLMs have a limited context window, large documents must be broken down into smaller, semantically coherent pieces, or “chunks” (Databricks, “Build an unstructured data pipeline for RAG”). A single executive order, for instance, might be split into several paragraphs or sections. The goal is to create chunks that are small enough to be processed efficiently but large enough to contain meaningful, self-contained information (AWS, “Dive deep into vector data stores using Amazon Bedrock Knowledge Bases”).
- Embedding Generation: Each chunk of text is then fed into an embedding model, such as a sentence transformer, to convert it into a vector embedding. This process transforms our entire corpus of federal documents into a collection of vectors, each representing a specific piece of information.
- Indexing : These generated embeddings are stored in a specialized vector database. This database is optimized for performing rapid similarity searches across millions or even billions of vectors. Along with the vector, it’s crucial to store metadata, such as the source document title or URL , which helps in providing citations and ensuring traceability in the final output.
Once this pipeline is complete, the RAG system is ready. As illustrated in Figure 5, when a user asks a question, the system first converts the query into a vector embedding using the same model. It then queries the vector database to find the chunks of text with the most similar embeddings—this is the spatial similarity search in action. These relevant chunks are then “augmented” to the original prompt and sent to the LLM, which uses this fresh, specific context to generate a grounded and accurate answer (Google Cloud, “What is Retrieval-Augmented Generation (RAG)?”). This process ensures that the model’s response is not a hallucination but is based on the provided data, effectively turning noise into intelligent, contextualized information.
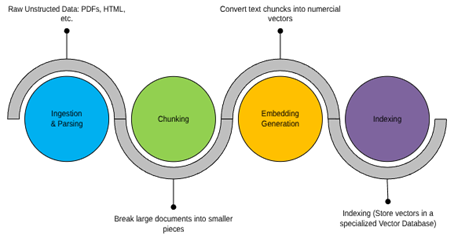
Figure 5: Key Stages of Data Preparation Pipeline
CONCLUDING WITH AN EXAMPLE: TASK-ORIENTED GENERATION FOR EXECUTIVE ORDERS
Now our system enables users to generate actionable, human-readable outputs based on U.S. Executive Orders by selecting a task type and providing contextual input. The AI processes this input in relation to a specified Executive Order (EO) and returns a structured response tailored to the user’s intent.
- User Input:
- Task Type: Audit Checklist
- Topic Context: Deadlines and Reporting
- Executive Order: EO 14150
- AI-Generated Output:
- A detailed Audit Checklist specifically addressing the Deadlines and Reporting requirements outlined in EO 14150.
Figure 6 shows how the output is made possible by semantic encoding of Executive Order content into vector embeddings, enabling precise chunk retrieval based on user intent and context.
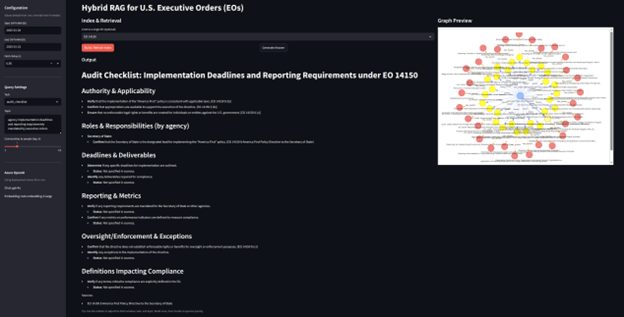
Figure 6: Semantic Encoding Output into Vector Embeddings
REFERENCES
“Build an unstructured data pipeline for RAG – Azure Databricks | Microsoft Learn.” Microsoft Learn, 3 Mar. 2025, https://learn.microsoft.com/en-us/azure/databricks/generative-ai/tutorials/ai-cookbook/quality-data-pipeline-rag.
“Dive deep into vector data stores using Amazon Bedrock Knowledge Bases.” AWS, 11 Oct. 2024, https://aws.amazon.com/blogs/machine-learning/dive-deep-into-vector-data-stores-using-amazon-bedrock-knowledge-bases/.
“Semantic Textual Similarity — Sentence Transformers documentation.” Sentence Transformers, sbert.net/docs/usage/semantic_textual_similarity.html.
“Six steps to improve your RAG application’s data foundation.” Databricks Community, 13 Nov. 2024, https://community.databricks.com/t5/technical-blog/six-steps-to-improve-your-rag-application-s-data-foundation/ba-p/97700.
“Supported embedding models available with watsonx.ai.” IBM, www.ibm.com/docs/en/watsonx-as-a-service?topic=models-supported-embedding.
“Understanding Retrieval Augmented Generation.” AWS Prescriptive Guidance, https://docs.aws.amazon.com/prescriptive-guidance/latest/retrieval-augmented-generation-options/what-is-rag.html .
“Vector Databases and Embeddings | Amazon Web Services (AWS).” AWS, aws.amazon.com/what-is/vector-databases/.
“Vector Search | Vertex AI.” Google Cloud, https://cloud.google.com/vertex-ai/docs/vector-search/overview.
“What is Embedding? | IBM.” IBM, 22 Dec. 2023, www.ibm.com/topics/embedding.
“What is Retrieval-Augmented Generation (RAG)? – Google Cloud.” Google Cloud, https://cloud.google.com/use-cases/retrieval-augmented-generation?hl=en.
“What is Vector Embedding? | IBM.” IBM, 12 June 2024, www.ibm.com/topics/vector-embedding.
“What are Vector Embeddings? – YouTube.” Amazon Web Services, 28 May 2025, https://www.youtube.com/watch?v=DCFEv-Duim4 .
“What is RAG? – Retrieval-Augmented Generation AI Explained.” AWS, aws.amazon.com/what-is/retrieval-augmented-generation/.